Смирнова О.О. «Оценка эффективности рекламной кампании». Учебное пособие. Москва 2005
© При использовании материалов ссылка на источник обязательна. Авторские права защищены.
ГЛАВА 5
≡≡≡≡≡≡≡≡≡≡≡≡≡≡≡
Классификация маркетинговых исследований. Социально демографические характеристики. Репрезентативность. Способы получения выборок. Рейтинг. Достоверность и надежность результатов, полученных в ходе маркетинговых и др. исследований.
≡≡≡≡≡≡≡≡≡≡≡≡≡≡≡
-
5.1. Социально демографические характеристики.
Исследования медиа бывают двух видов.
1. Исследования популярности медиа (рейтинги, и пр. медиаданные (МД)) собственно и называемые медиаисследованиями (МИ).
2. Исследования рекламы в медиа (мониторинг рекламы, и не только)
МИ базируются в основном на социологических исследованиях, а их достоверность такая же как и достоверность любой социологии зависит от: объема выборки, репрезентативности последней, методики исследования, и проч.
По периодичности МИ бывают:
1. Разовые (проводятся один раз).
2. Волновые (проводятся периодически "волнами" обычно с равными промежутками времени между волнами, периодичность обычно не чаще раза в квартал).
3. Непрерывные (проводятся постоянно в течении длительного промежутка времени (годы)).
Исследования любой периодичности имеют свои четкие границы применимости.
По способу получения данных:
1.Опросные (респондента опрашивают путем интервью, дневников, анкет. В любом случае в опросе так или иначе принимает участие другой человек)
2. Аппаратные (человек полностью исключен из процесса опроса. Респондент взаимодействует с прибором, который и снимает данные о его поведении)
Опросные методы проще и дешевле. Мы сами порой применяем их даже не догадываясь об этом. Когда Вы спрашиваете знакомых: "Ты смотрел ХХХ?" или "Ты читал вчера YYY?", - собственно Вы занимаетесь тем же, что и КОМКОН с Gallup, только они действуют в куда больших масштабах.
Но опросные методы имеют один недостаток. Человеческий фактор. Мы ведь тоже после вопроса "Ты читал вчера YYY?" часто говорим, "А зря, почитай!" а это уже давление на респондента. Кроме того, человеку свойственно работать медленно, ошибаться, быть подверженным смене настроения, иметь различные моральные качества, наконец. Все это не может не влиять на качество получаемых исходных данных.
Аппаратные методы (т.н. "пиплметры") очень дороги. Дорогие приборы. Прибор надо обслуживать, а главное - снимать с него данные.
Проще всего это делать по телефону. Но это тоже проблема. Телефонизация то у нас не поголовная. Кроме того респондентов очень трудно контролировать.
Включил я телевизор, убрал звук и ... заснул, а прибор продолжает фиксировать, что я смотрю телевизор, пока он не отключится сам, или я не проснусь. Когда я спал часов пять, то статистика это зафиксирует, а вот если "прикорнул на часок" - отследить невозможно.
Все эти недостатки компенсируются одним неоспоримым достоинством - данные получаются очень быстро (хоть в момент просмотра передачи) и с очень высокой точностью (в принципе можно разложить аудиторию ролика хоть по секундам).
Еще одна важная классификация: по длительности отношений с респондентом МИ бывают:
1.Панельные (респондент опрашивается регулярно а течение какого то срока).
2. С переменным составом респондентов (в выборке каждый раз новые люди).
Эта классификация характерна в основном для непрерывных (реже волновых) исследований. Характерным примером панельных МИ может служить TVметрическая панель Galup.
Пример исследования с переменным составом респондентов - телевизионные измерения ФОМ (сейчас они не проводятся).
Основным достоинством панельных МИ является дешевизна. Панель существует очень долго, время жизни респондента в ней - может быть от нескольких месяцев до нескольких лет. На подбор респондента в панель мы тратимся только один раз, тогда как при полном обновлении выборки мы каждый раз должны тратиться на подбор респондентов. Кроме того, в панельных исследованиях респондент обучается выполнять свои обязанности в панели (регистрация в пиплметрии, заполнение дневников, etc.) достаточно быстро. Значит меньше расходы на контроль. При переменном составе респондентов присутствие интервьюера почти всегда обязательно.
Как водится, недостатки - продолжение достоинств. "Старый" респондент частенько начинает "халявить" (например, заполняет дневник раз в два три дня, или за всех членов домохозяйства дневники заполняет один человек). С этим приходится бороться. Кроме того, панель, несколько сложнее поддерживать с точки зрения репрезентативности.
-
5.2. Социально демографические характеристики.
Теперь перечислим основные социально - демографические параметры в порядке убывания значимости:
Душевой доход поставлен на последнее место не потому что имеет наименьшую значимость, а потому, что данные по доходам не всегда валидны. Проблема в том, что в нашей стране не принято разглашать свои доходы. Есть и объективные трудности.
Во-первых, необходимо знать не просто доход а долю общего дохода домохозяйства, приходящуюся на каждого его (домохозяйства) члена, или душевой доход. Когда речь идет о панели эта проблема разрешима. А вот когда исследование разовое, да в нем еще принимает участие только один из членов домохозяйства, то ошибка в определении душевого дохода, обычно очень существенна. Вот почему разовые исследования так часто расходятся с панельными именно в данных по доходам. Естественно рекламистам важно знать эту характеристику как можно точнее, но ни чего не поделаешь, приходится смириться.
Во-вторых, наше общество чрезвычайно социально мобильно. Если сегодня человек работает на достаточно денежной работе, то завтра может ее потерять, или устроиться на еще более денежную. Сообщить это интервьюеру зачастую забывают, пока интервьюер не заметит изменений в быте домохозяйства. Но это все относится только к дневниковой панели. Для пиплметрической же панели это вообще почти невозможно отследить.
Несколько слов об остальных параметрах: социальное положение важно прежде всего потому, что определяет круг общения, который зачастую сильно влияет на медиапредпочтения. Образование тоже определяет медиапредпочтения, но в меньшей степени чем круг общения.
Таким образом мы получили ранжированный список соц.дем. параметров.
-
5.3. Репрезентативность
Если Вы хотите чтобы Ваши маркетинговые исследования действительно отражали медиапредпочтения всего населения, то совсем не достаточно опросить просто домохозяек, или старушек у подъездов. Логично предположить, что старушки и их юные внуки смотрят несколько разные телепередачи, или читают не одни и те же газеты. Значит, нужно выяснить мнение всех социально демографических групп населения.
Старая восточная мудрость гласит, "чтобы узнать вкус дыни не обязательно есть ее целиком". Совершенно справедливо и для социологии, но .при этом надо "знать как отрезать кусочек" на примере с дыней. Если мы отрежем кусочек вдоль "экватора" дыни, то мы ни чего не сможем узнать о вкусе около "полюсов", а вот если мы вырежем ломтик в меридиональном направлении, то весь спектр вкуса будет к нашим услугам. Осталось только не спеша попробовать и написать отчет. Социолог скажет, что такой ломтик был репрезентативен относительно "мередионального распределения вкуса дыни". Т.е. в ломтике представлены все пояса вкуса в той же пропорции, что и в самой дыне.
Точно так же и в социологии. Нам нужна выборка, в которой все группы населения представлены пропорционально их распределению в генеральной совокупности (ГС - в нашем случае это все те кого мы хотим исследовать).
Необходимо обратить внимания на то, что генеральная совокупность обязательно
должна описываться в заголовке любого исследования в явном виде. Например "Все население региона старше 13 лет" или "Городское население региона старше 10 лет" Если этого нет, мы не знаем границ применимости полученных цифр. Т.е. если в ГС 12% неработающих женщин, то и в выборке обязано быть 12%, если, в ГС шоферов автобусов 0.8%, то и в выборке должно быть столько же. Отсюда следует интересный вывод; "Ни одна выборка не является абсолютно репрезентативной!". Не думаю, что где-нибудь существует выборка репрезентативная по цвету глаз респондентов, или по форме ушей, это просто ни кому не нужно. А вот репрезентативность по наличию домашних животных не помешала бы. Поэтому, всегда указывают относительно каких параметров репрезентативна выборка.Также важно и то, что в описании выборки любого исследования обязательно должна присутствовать фраза "... выборка, репрезентативная по (набор соц.дем. параметров)"
5.3.1. Способы получения выборок.
Есть два основных способа получения выборки: абсолютно случайная выборка, и квотная выборка.
Представьте себе ведро в котором равномерно перемешаны шарики трех разных цветов, и самых разных размеров. Нам нужно узнать средний размер шариков каждого цвета. Мы зачерпываем горсть шариков (это и будет случайная выборка). Сортируем по цвету измеряем размер каждого и вычисляем средние по цветам. Но это только в том случае если шарики очень хорошо перемешаны. Если нет - возможны проблемы.
Та же история, но, мы знаем процентное содержание шариков каждого цвета (квоту) в ведре. Мы можем наугад отобрать по N1,N2, N3 (пропорционально их квотам) шариков каждого цвета (это и есть квотная выборка) измерить и получить средние по цветам. Так конечно надежнее, нет нужды думать о степени перемешанности по цвету. Но нужно знать квоту каждого цвета.
Но это все теория. Дело в том, что в реальной жизни очень трудно добиться абсолютной случайности. Поток пешеходов на улицах - имеет довольно строгую закономерность, в зависимости от части дня, конкретной точки, погодных условий, и еще кучи факторов. Расселение жильцов по квартирам тоже довольно закономерно. Случайную выборку получить крайне трудно. Приходится сильно исхитряться.
Наиболее применяем на практике комбинированный метод - случайная, квотная выборка. Это когда сперва
- делают случайную выборку,
- потом проверяют в ней квотность,
- а потом компенсируют нарушения квотности, тем или иным способом.
Итак, описание выборки мы теперь можем написать так "Случайная, квотная выборка, репрезентативная по (набор соц.дем. параметров)".
5.3.2. Рейтинг
Рейтинг - отношение числа людей ответивших положительно на вопрос о просмотре передачи (чтении газеты, и проч.), к объему выборки, выраженное в процентах.
Иными словами, если мы опросили 1 000 человек, и 253 сказали нам, что вчера смотрели программу "Время", то рейтинг вчерашнего "Времени" - 253/1 000 = 25.3%.
Рейтинг того же "Времени" среди мужчин - 152/480 = 31.7% (мужчин в популяции 48%, а ответили положительно, допустим 152 мужчины).
Рейтинг среди женщин соответственно - 101/520 = 19.4%.
По аналогии мы можем определить все соц.дем. характеристики данной передачи.
Часто можно встретить такое определение рейтинга "Рейтинг - отношение числа смотревших передачу к объему ГС", так вот, это неверное определение. Подобным образом можно определить рейтинг только путем референдума (всенародного опроса), а его вряд ли под силу провести даже самой крупной компании. Кроме того, подобное определение как бы исподволь внушает нам, что рейтинг является характеристикой всей ГС. Рейтинг характеризует только нашу выборку, а в каких взаимоотношениях он находится с ГС зависит от того, насколько наша выборка репрезентирует ГС, от методики исследования, объема выборки, и т.д.
Если вы сможете формализовать вашу целевую аудиторию (например, домохозяйки 20 - 50 лет) - то сможете вычислить рейтинг (и не только) в этой целевой аудитории, а следовательно узнать сколько же человек контактировало с Вашей рекламой: рейтинг в ЦГ надо умножить на объем ЦГ. Получится число людей из ЦГ смотревших данную передачу. Это называется проекцией рейтинга на население (в данном примере на ЦГ). Выражается эта величина обычно в тысячах человек и обозначается (000's).
И вот тут начинаются тонкости. Если мы возьмем ЦГ "мужчины и женщины в возрасте 16-20, с высшим образованием" то сами понимаете, рейтинг будет равен нулю. Не бывает таких (не есть конечно вундеркинды, но их очень мало и вряд ли он попали в выборку). Т.е. на очень мелких ЦГ медиаданные становятся невалидными.
Тут необходимо сказать о точности: есть одно негласное, хотя абсолютно верное правило. "Нельзя опираться на мнение менее чем 70 человек"! Это очень удобное правило. Им крайне легко пользоваться. Если мы встречаем рейтинг в 1.75%, знаем что выборка 1 000 человек, понятно, что данные некорректны. Это правило можно вполне строго доказать с помощью методов теории вероятности (В. Феллера "Введение в теорию вероятностей и ее приложения", том первый).
Теперь о половинке человека. Такое частенько случается с медиаметристами. И происходит это от особенностей расчетов проводимых при получении медиахарактеристик. Итак, на выборке в 1000, валидны рейтинги только более 7% все, что ниже - невалидны (т.е. имеют очень большой доверительный интервал). Доверительный интервал расширяется при уменьшении рейтинга и при уменьшении объема выборки. Да такие рейтинги тоже несут некоторую информацию, однако доверять им можно только с некоторой оглядкой.
Отсюда один интересный момент. Чем сильнее мы ограничиваем ЦГ пересечением соц.дем. параметров, тем менее точны в этой ЦГ рейтинги. Действительно объем выборки в каждой соц.дем. группе меньше чем во всей выборке, а в пересечении соц.дем. групп еще меньше. Значит в соц.дем. группе представленной в выборке менее чем 70 респондентами рейтинги - ни какого смысла не имеют.
Теперь мы можем написать наше описание выборки например так: "В исследовании использована случайная, квотная выборка, репрезентативная по полу и возрасту. Объем выборки - 1 500 человек." и далее "Генеральная совокупность - все городское население Тверской области. (города с населением более 100 000 человек" Т.е. в этом описании должны быть четко обозначены основные параметры исследования, позволяющие судить подходит нам результаты этого исследование для решения наших задач или нет.
-
5.4. Достоверность и надежность результатов, полученных в ходе маркетинговых и др. исследований.
Различные рекламные агентства составляют медиа-планы, высчитывают охват, частоту, индексы соответствия и многие другие столь же интересные показатели, чтобы потом клиент мог сравнить эффективность предлагаемых ему планов. Сравниваются же планы именно на основании соотнесения этих показателей.
Казалось бы, все логично, славная наука медиапланирования начала свое бурное и стремительное развитие на нашей российской почве. Но, как это часто бывает, не учтены некоторые национальные особенности, а именно - достоверность и изначальные погрешности данных, на которые в начале своей работы опирается специалист по медиапланированию.
Итак, что же получается, если пунктуально все посчитать?
Вопрос первый - какая выборка обеспечит уверенные результаты для работы со средствами рекламы, имеющими рейтинги от 1 до 5? А рейтинги от 1 до 5 являются весьма важными, поскольку для прессы, например, из более 100 изданий, распространяющихся по России, около 80 имеют рейтинги в этих пределах.
Так вот, пусть объем выборки будет такой, чтобы получаемый рейтинг с вероятностью 90% имел точность + 0.5. Так вот, чтобы обеспечить такие параметры, надо опросить не менее 27 000 человек. Замечу еще, что повышение точности в два раза ведет к увеличению объема выборки в четыре раза (В. Феллер "Введение в теорию вероятностей и ее приложения", том первый).
Зная, какого объема волновые исследования представлены на российском рынке, попытаемся оценить точность представляемых данных. Отмечу сразу, что речь пойдет об объеме выборки в одной волне, а не во всем исследовании за, скажем, год, поскольку иначе часть данных, собранная год назад, уже может устареть.
В таблице, приведенной ниже, даны доверительные интервалы, в которые попадает с вероятностью 95% значение рейтинга в опросе, если в генеральной совокупности рейтинг такой, как указан в заголовке таблицы. Иначе говоря, если среди населения в целом рейтинг издания равен единице, то при заданном объеме выборке он окажется в пределах, указанных в процентах от самого рейтинга в таблице. Напомню еще, что доверительным интервалом называют тот интервал значений, в который с заданной вероятностью попадет рейтинг в выборке, если в генеральной совокупности он таков, как указано в заголовке таблицы.
Таблица
|
объем выборки |
довери- тельный интервал для рейтинга 1 |
довери- тельный интервал для рейтинга 3 |
довери- тельный интервал для рейтинга 5 |
довери- тельный интервал для рейтинга 10 |
довери- тельный интервал для рейтинга 20 |
|
1 000 |
+ 62.8% |
+ 36% |
+ 27.5% |
+ 19% |
+ 12.6% |
|
3 000 |
+ 36.3% |
+ 20% |
+ 16% |
+ 11% |
+ 7.3% |
|
5 000 |
+ 28.0% |
+ 16% |
+ 1 2% |
+ 8.5% |
+ 5.7% |
|
10 000 |
+ 20.0% |
+ 11.4% |
+ 8 .7% |
+ 6% |
+ 4% |
|
15 000 |
+ 16.2% |
+ 9.3% |
+ 7% |
+ 5% |
+ 3.3% |
Применительно к составлению медиа-планов это означает, что при выборе рекламоносителя на основании исследования медиа-предпочтений с выборкой, например, 1000 респондентов, статистически неразличимыми оказываются рейтинги в интервалах от 03 до 1.6 (т.е. берем один процент от 1000, сначала отнимаем значение погрешности - 62.8%, получаем .37 , затем прибавляем 62.8%, получаем 1.63) или от 3.7 до 6.35 (т.е. 5+ 27.5%, получается аналогично), при исследовании объемом 5 000 респондентов, неразличимы будут рейтинги в интервалах от 0.7 до 1.3 (т.е. 1+ 28%%, получается аналогично), или от 4.4 до 5.6 (т.е. 5+ 12%%, получается аналогично). Ну, и так далее.
С этой информацией в руках попробуем решить простенькую задачку.
Пусть, на основании исследования телесмотрения, например, в Москве, с объемом выборки 1000 респондентов, составлен медиа-план включающий:
- 2 спотов с рейтингом в целевой группе - 3 процента,
- 10 спотов с рейтингом 10,
- 5 спотов с рейтингом 20.
Целевая же группа составляет 50% всей аудитории.
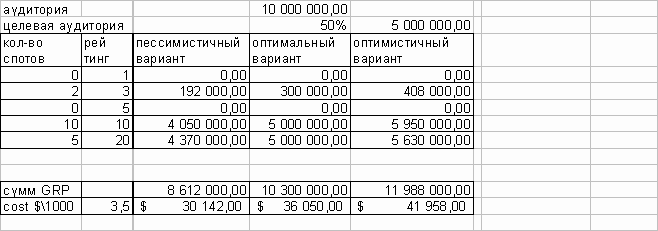
Более подробно результаты этой таблицы можно описать так: во-первых, для объема выборки 500 таким же образом, как в таблице 1 определяется доверительный интервал. Для рейтинга 3 это будет + 36%; для рейтинга 10 - + 26.8%; для рейтинга 20 - + 12.6.
Теперь посчитаем суммарное значение GRP для этого медиа-плана. Два медиа-плана, построенные на выборке в 1000 респондентов для целевой группы, составляющей половину генеральной совокупности, статистически неразличимы, если они используют рекламоносители с рейтингами не более 20, но имеют разницу в показателях охвата целевой группы около 30%.
Возьмем другой пример и другой срез данных. Речь пойдет о прессе. Пусть мы имеем исследование медиа-предпочтений по России в целом с объемом выборки 10 000 респондентов, и хотим оценить издание с тиражом 200 000 и рейтингом среди населения в целом - 3%. Итак, если примерно оценить население России в 150 млн. человек, и предположить, что две трети из них имеют возможность и способность читать (по возрасту и состоянию здоровья), получается вот что: тираж в 200 000 экз. должно прочитать около 3 млн. человек (3% населения, способного читать), то есть каждый экземпляр прочитывает в среднем 15 (!) человек. Посмотрим с другой стороны: если каждый номер в среднем читает 3 человека (более ли менее разумное число), то, восстанавливая по данным опроса численность генеральной совокупности, получим, что население России, которое в состоянии читать, составляет 20 млн. человек, т.е. около 13% всего населения России.
Но у следующего за моими рассуждениями доверчивого читателя, наверное, давно уже вертится в голове вопрос: "Ну, хорошо, в том, что все у нас не как у людей ты меня убедили, а дальше что?"
Попробую ответить. Во-первых, если сравниваются два плана по статистическим показателям (GRP, частотному распределению, охватам, индексам соответствия и т.д.), то прежде, чем делать вывод об их качестве, надо посчитать погрешности в данных или хотя бы привести значения объемов выборок в используемых исследованиях.
Во-вторых, прежде чем перенимать западные технологии медиа-планирования, честно ответить себе и окружающим на вопрос, применимы ли они на наших данных с вот такими погрешностями.
В-третьих, не стоит сразу кидаться с обвинениями в адрес фирм, собирающих и продающих такие данные. Собственно, их развитие началось примерно тогда же, когда и наше с вами, уважаемые коллеги. И такое поражение в данных - не от непрофессионализма, а, скорее, оттого, что даже исследования в таком объеме стоят весьма недешево, а уж если сделать опрос представительным во всех отношениях, то его вообще никто купить не сможет.
И последнее, как же работать, если под ногами нет твердой почвы из статистических данных? Как известно (например, из трудов математика Гельфанда), в таких случаях помогает система экспертных оценок. Не думайте, что речь идет о возврате к темному прошлому, когда медиа-плэннер, посмотрев в небо, рекомендовал клиенту размещать рекламу здесь или там, что и называлось "по данным экспертных оценок". Нет, речь о том, чтобы провести представительный опрос экспертов (проект такого опроса у нас уже есть), например, так, как это описывается в "Рабочей книге социолога". А поручить его проведение имеет смысл одной из тех фирм, у которых мы все сейчас покупаем панельные и волновые исследования медиа-предпочтений.
В завершение, для тех, у кого проснется такой же въедливый интерес к оценкам достоверности, приведенным выше, опишу честно и подробно, из каких предположений выводились эти оценки.
Итак, первое предположение - ответы на вопросы исследования медиа-предпочтений можно трактовать как испытания Бернулли. Второе - распределение респондентов (читателей, зрителей, слушателей) для каждого средства рекламы можно считать нормальным. И, наконец, третье - выборка респондентов исследования из генеральной совокупности производилась случайным образом.
Напомню одну интересную особенность вычисления погрешностей в статистических исследованиях - погрешность данных выборочного исследования зависит только от исследуемой вероятности и от объема выборки, но, увы, не от объема генеральной совокупности. Практически это значит, что для получения данных о рейтинге рекламоносителя с желаемой точностью следует брать одинаковую выборку, как для Москвы, так и для России в целом. И еще - в квотированной выборке погрешность не будет меньше, чем в просто случайной.
Смирнова О.О. «Оценка эффективности рекламной кампании». Учебное пособие. Москва 2005
© При использовании материалов ссылка на источник обязательна. Авторские права защищены.